1. Import and observe dataset
We all love watching movies! There are some movies we like, some we don't. Most people have a preference for movies of a similar genre. Some of us love watching action movies, while some of us like watching horror. Some of us like watching movies that have ninjas in them, while some of us like watching superheroes.
Movies within a genre often share common base parameters. Consider the following two movies:


Both movies, 2001: A Space Odyssey and Close Encounters of the Third Kind, are movies based on aliens coming to Earth. I've seen both, and they indeed share many similarities. We could conclude that both of these fall into the same genre of movies based on intuition, but that's no fun in a data science context. In this notebook, we will quantify the similarity of movies based on their plot summaries available on IMDb and Wikipedia, then separate them into groups, also known as clusters. We'll create a dendrogram to represent how closely the movies are related to each other.
Let's start by importing the dataset and observing the data provided.
# Import modules
import numpy as np
import pandas as pd
import nltk
# Set seed for reproducibility
np.random.seed(5)
# Read in IMDb and Wikipedia movie data (both in same file)
movies_df = pd.read_csv('datasets/movies.csv')
print("Number of movies loaded: %s " % (len(movies_df)))
# Display the data
movies_df
Number of movies loaded: 100
| rank | title | genre | wiki_plot | imdb_plot | |
|---|---|---|---|---|---|
| 0 | 0 | The Godfather | [u' Crime', u' Drama'] | On the day of his only daughter's wedding, Vit... | In late summer 1945, guests are gathered for t... |
| 1 | 1 | The Shawshank Redemption | [u' Crime', u' Drama'] | In 1947, banker Andy Dufresne is convicted of ... | In 1947, Andy Dufresne (Tim Robbins), a banker... |
| 2 | 2 | Schindler's List | [u' Biography', u' Drama', u' History'] | In 1939, the Germans move Polish Jews into the... | The relocation of Polish Jews from surrounding... |
| 3 | 3 | Raging Bull | [u' Biography', u' Drama', u' Sport'] | In a brief scene in 1964, an aging, overweight... | The film opens in 1964, where an older and fat... |
| 4 | 4 | Casablanca | [u' Drama', u' Romance', u' War'] | It is early December 1941. American expatriate... | In the early years of World War II, December 1... |
| 5 | 5 | One Flew Over the Cuckoo's Nest | [u' Drama'] | In 1963 Oregon, Randle Patrick "Mac" McMurphy ... | In 1963 Oregon, Randle Patrick McMurphy (Nicho... |
| 6 | 6 | Gone with the Wind | [u' Drama', u' Romance', u' War'] | \nPart 1\n \n Part 1 Part 1 \n \n On the... | The film opens in Tara, a cotton plantation ow... |
| 7 | 7 | Citizen Kane | [u' Drama', u' Mystery'] | \n\n\n\nOrson Welles as Charles Foster Kane\n\... | It's 1941, and newspaper tycoon Charles Foster... |
| 8 | 8 | The Wizard of Oz | [u' Adventure', u' Family', u' Fantasy', u' Mu... | The film starts in sepia-tinted Kansas in the ... | Dorothy Gale (Judy Garland) is an orphaned tee... |
| 9 | 9 | Titanic | [u' Drama', u' Romance'] | In 1996, treasure hunter Brock Lovett and his ... | In 1996, treasure hunter Brock Lovett and his ... |
| 10 | 10 | Lawrence of Arabia | [u' Adventure', u' Biography', u' Drama', u' H... | ] \n The film is presented in two parts, s... | In 1935, T. E. Lawrence (Peter O'Toole) is kil... |
| 11 | 11 | The Godfather: Part II | [u' Crime', u' Drama'] | \nIn 1901 Corleone, Sicily, nine-year-old Vito... | The Godfather Part II presents two parallel st... |
| 12 | 12 | Psycho | [u' Horror', u' Mystery', u' Thriller'] | Patrick Bateman is a wealthy investment banker... | In a Phoenix hotel room on a Friday afternoon,... |
| 13 | 13 | Sunset Blvd. | [u' Drama', u' Film-Noir'] | At a Sunset Boulevard mansion, the body of Joe... | The film opens with the camera tracking down S... |
| 14 | 14 | Vertigo | [u' Mystery', u' Romance', u' Thriller'] | ridge, Fort Point\n\n \n \n\n\n"Madeleine" a... | A woman's face gives way to a kaleidoscope of ... |
| 15 | 15 | On the Waterfront | [u' Crime', u' Drama'] | Mob-connected union boss Johnny Friendly (Lee ... | Terry Malloy (Marlon Brando) once dreamt of be... |
| 16 | 16 | Forrest Gump | [u' Drama', u' Romance'] | While waiting at a bus stop in 1981, Forrest G... | The film begins with a feather falling to the ... |
| 17 | 17 | The Sound of Music | [u' Biography', u' Drama', u' Family', u' Musi... | In 1938, while living as a young postulant at ... | The widowed, retired Austrian naval officer, C... |
| 18 | 18 | West Side Story | [u' Crime', u' Drama', u' Musical', u' Romance... | ] ] \n In the West Side's Lincoln Square ne... | A fight set to music between an American gang,... |
| 19 | 19 | Star Wars | [u' Action', u' Adventure', u' Fantasy', u' Sc... | The galaxy is in a civil war, and spies for th... | \nNote: Italicized paragraphs denote scenes ad... |
| 20 | 20 | E.T. the Extra-Terrestrial | [u' Adventure', u' Family', u' Sci-Fi'] | In a California forest, a group of alien botan... | In a forested area overlooking a sprawling sub... |
| 21 | 21 | 2001: A Space Odyssey | [u' Mystery', u' Sci-Fi'] | The film consists of four major sections, all ... | To Richard Strauss' tone poem "Thus Spake Zara... |
| 22 | 22 | The Silence of the Lambs | [u' Crime', u' Drama', u' Thriller'] | is pulled from her training at the FBI Academy... | Promising FBI Academy student Clarice Starling... |
| 23 | 23 | Chinatown | [u' Drama', u' Mystery', u' Thriller'] | A woman identifying herself as Evelyn Mulwray ... | Set in 1937 Los Angeles, a private investigato... |
| 24 | 24 | The Bridge on the River Kwai | [u' Adventure', u' Drama', u' War'] | In World War II, British prisoners arrive at a... | this synopsis is primarily from the wikipedia ... |
| 25 | 25 | Singin' in the Rain | [u' Comedy', u' Musical', u' Romance'] | Don Lockwood is a popular silent film star wit... | Don Lockwood (Gene Kelly) is a popular silent ... |
| 26 | 26 | It's a Wonderful Life | [u' Drama', u' Family', u' Fantasy'] | \n\n\n\nDonna Reed (as Mary Bailey) and James ... | This movie is about a divine intervention by a... |
| 27 | 27 | Some Like It Hot | [u' Comedy'] | It is February 1929 in the city of Chicago. Jo... | Joe and Jerry, a saxophonist and bassist, resp... |
| 28 | 28 | 12 Angry Men | [u' Drama'] | The story begins in a New York City courthous... | A teenaged Hispanic boy has just been tried fo... |
| 29 | 29 | Dr. Strangelove or: How I Learned to Stop Worr... | [u' Comedy', u' War'] | United States Air Force Brigadier General Jack... | At the Burpelson U.S. Air Force Base somewhere... |
| ... | ... | ... | ... | ... | ... |
| 70 | 70 | Rain Man | [u' Drama'] | Charlie Babbitt is in the middle of importing ... | Charlie Babbitt (Tom Cruise), a Los Angeles ca... |
| 71 | 71 | Annie Hall | [u' Comedy', u' Drama', u' Romance'] | The comedian Alvy Singer (Woody Allen) is tryi... | Annie Hall is a film about a comedian, Alvy Si... |
| 72 | 72 | Out of Africa | [u' Biography', u' Drama', u' Romance'] | The story begins in 1913 in Denmark, when Kare... | [Out Of Africa]A well-heeled Danish lady goes ... |
| 73 | 73 | Good Will Hunting | [u' Drama'] | Twenty-year-old Will Hunting (Damon) of South ... | Though Will Hunting (Matt Damon) has genius-le... |
| 74 | 74 | Terms of Endearment | [u' Comedy', u' Drama'] | Aurora Greenway (Shirley MacLaine) and her dau... | NaN |
| 75 | 75 | Tootsie | [u' Comedy', u' Drama', u' Romance'] | Michael Dorsey (Dustin Hoffman) is a respected... | Michael Dorsey is an actor living and working ... |
| 76 | 76 | Fargo | [u' Crime', u' Drama', u' Thriller'] | In the winter of 1987, Minneapolis car salesma... | The movie opens with a car towing a new tan Ol... |
| 77 | 77 | Giant | [u' Drama', u' Romance'] | Jordan "Bick" Benedict (Rock Hudson), head of ... | In the early 1920s, Jordan "Bick" Benedict (Ro... |
| 78 | 78 | The Grapes of Wrath | [u' Drama'] | The film opens with Tom Joad (Henry Fonda), re... | After serving four years in prison for killing... |
| 79 | 79 | Shane | [u' Drama', u' Romance', u' Western'] | \n\n\n\nAlan Ladd and Jean Arthur\n\n \n \n\... | NaN |
| 80 | 80 | The Green Mile | [u' Crime', u' Drama', u' Fantasy', u' Mystery'] | In a Louisiana nursing home in 1999, Paul Edge... | The movie begins with an old man named Paul Ed... |
| 81 | 81 | Close Encounters of the Third Kind | [u' Drama', u' Sci-Fi'] | In the Sonoran Desert, French scientist Claude... | In what appers to be the Sonoran Desert; in or... |
| 82 | 82 | Network | [u' Drama'] | Howard Beale, the longtime anchor of the Union... | NaN |
| 83 | 83 | Nashville | [u' Drama', u' Music'] | The overarching plot takes place over five day... | The overarching plot takes place over five day... |
| 84 | 84 | The Graduate | [u' Comedy', u' Drama', u' Romance'] | Benjamin Braddock, going on from twenty to twe... | The film explores the life of 21-year-old Ben ... |
| 85 | 85 | American Graffiti | [u' Comedy', u' Drama'] | In late August 1962 recent high school graduat... | It's the last night of the summer in 1962, and... |
| 86 | 86 | Pulp Fiction | [u' Crime', u' Drama', u' Thriller'] | The Diner" "Prologue—The Diner" \n "Pumpkin... | Late one morning in the Hawthorne Grill, a res... |
| 87 | 87 | The African Queen | [u' Adventure', u' Romance', u' War'] | Robert Morley and Katharine Hepburn play Samue... | An English spinster, Rose (Katharine Hepburn),... |
| 88 | 88 | Stagecoach | [u' Adventure', u' Western'] | In 1880, a motley group of strangers boards th... | NaN |
| 89 | 89 | Mutiny on the Bounty | [u' Adventure', u' Drama', u' History'] | In the year 1787, the Bounty sets sail from En... | NaN |
| 90 | 90 | The Maltese Falcon | [u' Drama', u' Film-Noir', u' Mystery'] | \n\n\nIn 1539 the Knight Templars of Malta, pa... | Private eye Sam Spade and his partner Miles Ar... |
| 91 | 91 | A Clockwork Orange | [u' Crime', u' Drama', u' Sci-Fi'] | In futuristic London, Alex DeLarge is the lead... | A bit of the old ultra-violence".London, Engla... |
| 92 | 92 | Taxi Driver | [u' Crime', u' Drama'] | Travis Bickle, an honorably discharged U.S. Ma... | Travis Bickle (Robert De Niro) goes to a New Y... |
| 93 | 93 | Wuthering Heights | [u' Drama', u' Romance'] | A traveller named Lockwood (Miles Mander) is c... | NaN |
| 94 | 94 | Double Indemnity | [u' Crime', u' Drama', u' Film-Noir', u' Thril... | \n\n\n\nNeff confesses into a Dictaphone.\n\n ... | Walter Neff (MacMurray) is a successful insura... |
| 95 | 95 | Rebel Without a Cause | [u' Drama'] | \n\n\n\nJim Stark is in police custody.\n\n \... | Shortly after moving to Los Angeles with his p... |
| 96 | 96 | Rear Window | [u' Mystery', u' Thriller'] | \n\n\n\nJames Stewart as L.B. Jefferies\n\n \... | L.B. "Jeff" Jeffries (James Stewart) recuperat... |
| 97 | 97 | The Third Man | [u' Film-Noir', u' Mystery', u' Thriller'] | \n\n\n\nSocial network mapping all major chara... | Sights of Vienna, Austria, flash across the sc... |
| 98 | 98 | North by Northwest | [u' Mystery', u' Thriller'] | Advertising executive Roger O. Thornhill is mi... | At the end of an ordinary work day, advertisin... |
| 99 | 99 | Yankee Doodle Dandy | [u' Biography', u' Drama', u' Musical'] | \n In the early days of World War II, Cohan ... | NaN |
100 rows × 5 columns
2. Combine Wikipedia and IMDb plot summaries
The dataset we imported currently contains two columns titled wiki_plot and imdb_plot. They are the plot found for the movies on Wikipedia and IMDb, respectively. The text in the two columns is similar, however, they are often written in different tones and thus provide context on a movie in a different manner of linguistic expression. Further, sometimes the text in one column may mention a feature of the plot that is not present in the other column. For example, consider the following plot extracts from The Godfather:
- Wikipedia: "On the day of his only daughter's wedding, Vito Corleone"
- IMDb: "In late summer 1945, guests are gathered for the wedding reception of Don Vito Corleone's daughter Connie"
While the Wikipedia plot only mentions it is the day of the daughter's wedding, the IMDb plot also mentions the year of the scene and the name of the daughter.
Let's combine both the columns to avoid the overheads in computation associated with extra columns to process.
# Combine wiki_plot and imdb_plot into a single column
movies_df['plot'] = movies_df['wiki_plot'].astype(str) + "\n" + \
movies_df['imdb_plot'].astype(str)
# Inspect the new DataFrame
movies_df.head()
| rank | title | genre | wiki_plot | imdb_plot | plot | |
|---|---|---|---|---|---|---|
| 0 | 0 | The Godfather | [u' Crime', u' Drama'] | On the day of his only daughter's wedding, Vit... | In late summer 1945, guests are gathered for t... | On the day of his only daughter's wedding, Vit... |
| 1 | 1 | The Shawshank Redemption | [u' Crime', u' Drama'] | In 1947, banker Andy Dufresne is convicted of ... | In 1947, Andy Dufresne (Tim Robbins), a banker... | In 1947, banker Andy Dufresne is convicted of ... |
| 2 | 2 | Schindler's List | [u' Biography', u' Drama', u' History'] | In 1939, the Germans move Polish Jews into the... | The relocation of Polish Jews from surrounding... | In 1939, the Germans move Polish Jews into the... |
| 3 | 3 | Raging Bull | [u' Biography', u' Drama', u' Sport'] | In a brief scene in 1964, an aging, overweight... | The film opens in 1964, where an older and fat... | In a brief scene in 1964, an aging, overweight... |
| 4 | 4 | Casablanca | [u' Drama', u' Romance', u' War'] | It is early December 1941. American expatriate... | In the early years of World War II, December 1... | It is early December 1941. American expatriate... |
3. Tokenization
Tokenization is the process by which we break down articles into individual sentences or words, as needed. Besides the tokenization method provided by NLTK, we might have to perform additional filtration to remove tokens which are entirely numeric values or punctuation.
While a program may fail to build context from "While waiting at a bus stop in 1981" (Forrest Gump), because this string would not match in any dictionary, it is possible to build context from the words "while", "waiting" or "bus" because they are present in the English dictionary.
Let us perform tokenization on a small extract from The Godfather.
# Tokenize a paragraph into sentences and store in sent_tokenized
sent_tokenized = [sent for sent in nltk.sent_tokenize("""
Today (May 19, 2016) is his only daughter's wedding.
Vito Corleone is the Godfather.
""")]
# Word Tokenize first sentence from sent_tokenized, save as words_tokenized
words_tokenized = [word for word in nltk.word_tokenize(sent_tokenized[0])]
# Remove tokens that do not contain any letters from words_tokenized
import re
filtered = [word for word in words_tokenized if re.search('[A-Za-z]', word)]
# Display filtered words to observe words after tokenization
filtered
['Today', 'May', 'is', 'his', 'only', 'daughter', "'s", 'wedding']
4. Stemming
Stemming is the process by which we bring down a word from its different forms to the root word. This helps us establish meaning to different forms of the same words without having to deal with each form separately. For example, the words 'fishing', 'fished', and 'fisher' all get stemmed to the word 'fish'.
Consider the following sentences:
- "Young William Wallace witnesses the treachery of Longshanks" ~ Gladiator
- "escapes to the city walls only to witness Cicero's death" ~ Braveheart
Instead of building separate dictionary entries for both witnesses and witness, which mean the same thing outside of quantity, stemming them reduces them to 'wit'.
There are different algorithms available for stemming such as the Porter Stemmer, Snowball Stemmer, etc. We shall use the Snowball Stemmer.
# Import the SnowballStemmer to perform stemming
# ... YOUR CODE FOR TASK 4 ...
from nltk.stem.snowball import SnowballStemmer
# Create an English language SnowballStemmer object
stemmer = SnowballStemmer("english")
# Print filtered to observe words without stemming
print("Without stemming: ", filtered)
# Stem the words from filtered and store in stemmed_words
stemmed_words = [stemmer.stem(word) for word in filtered]
# Print the stemmed_words to observe words after stemming
print("After stemming: ", stemmed_words)
Without stemming: ['Today', 'May', 'is', 'his', 'only', 'daughter', "'s", 'wedding']
After stemming: ['today', 'may', 'is', 'his', 'onli', 'daughter', "'s", 'wed']
5. Club together Tokenize & Stem
We are now able to tokenize and stem sentences. But we may have to use the two functions repeatedly one after the other to handle a large amount of data, hence we can think of wrapping them in a function and passing the text to be tokenized and stemmed as the function argument. Then we can pass the new wrapping function, which shall perform both tokenizing and stemming instead of just tokenizing, as the tokenizer argument while creating the TF-IDF vector of the text.
What difference does it make though? Consider the sentence from the plot of The Godfather: "Today (May 19, 2016) is his only daughter's wedding." If we do a 'tokenize-only' for this sentence, we have the following result:
'today', 'may', 'is', 'his', 'only', 'daughter', "'s", 'wedding'
But when we do a 'tokenize-and-stem' operation we get:
'today', 'may', 'is', 'his', 'onli', 'daughter', "'s", 'wed'
All the words are in their root form, which will lead to a better establishment of meaning as some of the non-root forms may not be present in the NLTK training corpus.
# Define a function to perform both stemming and tokenization
def tokenize_and_stem(text):
# Tokenize by sentence, then by word
tokens = [sent for sent in nltk.word_tokenize(text)]
# Filter out raw tokens to remove noise
filtered_tokens = [token for token in tokens if re.search('[a-zA-Z]', token)]
# Stem the filtered_tokens
stems = [stemmer.stem(stem) for stem in filtered_tokens]
return stems
words_stemmed = tokenize_and_stem("Today (May 19, 2016) is his only daughter's wedding.")
print(words_stemmed)
['today', 'may', 'is', 'his', 'onli', 'daughter', "'s", 'wed']
6. Create TfidfVectorizer
Computers do not understand text. These are machines only capable of understanding numbers and performing numerical computation. Hence, we must convert our textual plot summaries to numbers for the computer to be able to extract meaning from them. One simple method of doing this would be to count all the occurrences of each word in the entire vocabulary and return the counts in a vector. Enter CountVectorizer.
Consider the word 'the'. It appears quite frequently in almost all movie plots and will have a high count in each case. But obviously, it isn't the theme of all the movies! Term Frequency-Inverse Document Frequency (TF-IDF) is one method which overcomes the shortcomings of CountVectorizer. The Term Frequency of a word is the measure of how often it appears in a document, while the Inverse Document Frequency is the parameter which reduces the importance of a word if it frequently appears in several documents.
For example, when we apply the TF-IDF on the first 3 sentences from the plot of The Wizard of Oz, we are told that the most important word there is 'Toto', the pet dog of the lead character. This is because the movie begins with 'Toto' biting someone due to which the journey of Oz begins!
In simplest terms, TF-IDF recognizes words which are unique and important to any given document. Let's create one for our purposes.
# Import TfidfVectorizer to create TF-IDF vectors
# ... YOUR CODE FOR TASK 6 ...
from sklearn.feature_extraction.text import TfidfVectorizer
# Instantiate TfidfVectorizer object with stopwords and tokenizer
#tfidf_vectorizer = TfidfVectorizer(stopwords = 'english', tokenizer = tokenize_and_stem())
# parameters for efficient processing of text
tfidf_vectorizer = TfidfVectorizer(max_df=0.8, max_features=200000,
min_df=0.2, stop_words='english',
use_idf=True, tokenizer= tokenize_and_stem,
ngram_range=(1,3))
7. Fit transform TfidfVectorizer
Once we create a TF-IDF Vectorizer, we must fit the text to it and then transform the text to produce the corresponding numeric form of the data which the computer will be able to understand and derive meaning from. To do this, we use the fit_transform() method of the TfidfVectorizer object.
If we observe the TfidfVectorizer object we created, we come across a parameter stopwords. 'stopwords' are those words in a given text which do not contribute considerably towards the meaning of the sentence and are generally grammatical filler words. For example, in the sentence 'Dorothy Gale lives with her dog Toto on the farm of her Aunt Em and Uncle Henry', we could drop the words 'her' and 'the', and still have a similar overall meaning to the sentence. Thus, 'her' and 'the' are stopwords and can be conveniently dropped from the sentence.
On setting the stopwords to 'english', we direct the vectorizer to drop all stopwords from a pre-defined list of English language stopwords present in the nltk module. Another parameter, ngram_range, defines the length of the ngrams to be formed while vectorizing the text.
# Fit and transform the tfidf_vectorizer with the "plot" of each movie
# to create a vector representation of the plot summaries
tfidf_matrix = tfidf_vectorizer.fit_transform([x for x in movies_df["plot"]])
print(tfidf_matrix.shape)
(100, 564)
8. Import KMeans and create clusters
To determine how closely one movie is related to the other by the help of unsupervised learning, we can use clustering techniques. Clustering is the method of grouping together a number of items such that they exhibit similar properties. According to the measure of similarity desired, a given sample of items can have one or more clusters.
A good basis of clustering in our dataset could be the genre of the movies. Say we could have a cluster '0' which holds movies of the 'Drama' genre. We would expect movies like Chinatown or Psycho to belong to this cluster. Similarly, the cluster '1' in this project holds movies which belong to the 'Adventure' genre (Lawrence of Arabia and the Raiders of the Lost Ark, for example).
K-means is an algorithm which helps us to implement clustering in Python. The name derives from its method of implementation: the given sample is divided into K clusters where each cluster is denoted by the mean of all the items lying in that cluster.
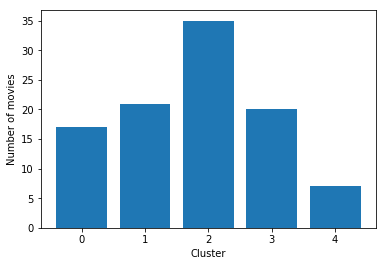
We get the following distribution for the clusters:
# Import k-means to perform clusters
from sklearn.cluster import KMeans
# Create a KMeans object with 5 clusters and save as km
km = KMeans(n_clusters=5)
# Fit the k-means object with tfidf_matrix
km.fit(tfidf_matrix)
clusters = km.labels_.tolist()
# Create a column cluster to denote the generated cluster for each movie
movies_df["cluster"] = clusters
# Display number of films per cluster (clusters from 0 to 4)
movies_df['cluster'].value_counts()
2 35
1 21
3 20
0 17
4 7
Name: cluster, dtype: int64
9. Calculate similarity distance
Consider the following two sentences from the movie The Wizard of Oz:
"they find in the Emerald City"
"they finally reach the Emerald City"
If we put the above sentences in a CountVectorizer, the vocabulary produced would be "they, find, in, the, Emerald, City, finally, reach" and the vectors for each sentence would be as follows:
1, 1, 1, 1, 1, 1, 0, 0
1, 0, 0, 1, 1, 1, 1, 1
When we calculate the cosine angle formed between the vectors represented by the above, we get a score of 0.667. This means the above sentences are very closely related. Similarity distance is 1 - cosine similarity angle. This follows from that if the vectors are similar, the cosine of their angle would be 1 and hence, the distance between then would be 1 - 1 = 0.
Let's calculate the similarity distance for all of our movies.
# Import cosine_similarity to calculate similarity of movie plots
from sklearn.metrics.pairwise import cosine_similarity
# Calculate the similarity distance
similarity_distance = 1 - cosine_similarity(tfidf_matrix)
10. Import Matplotlib, Linkage, and Dendrograms
We shall now create a tree-like diagram (called a dendrogram) of the movie titles to help us understand the level of similarity between them visually. Dendrograms help visualize the results of hierarchical clustering, which is an alternative to k-means clustering. Two pairs of movies at the same level of hierarchical clustering are expected to have similar strength of similarity between the corresponding pairs of movies. For example, the movie Fargo would be as similar to North By Northwest as the movie Platoon is to Saving Private Ryan, given both the pairs exhibit the same level of the hierarchy.
Let's import the modules we'll need to create our dendrogram.
# Import matplotlib.pyplot for plotting graphs
# ... YOUR CODE FOR TASK 10 ...
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import linkage, dendrogram
# Configure matplotlib to display the output inline
%matplotlib inline
# Import modules necessary to plot dendrogram
# ... YOUR CODE FOR TASK 10 ...
DEBUG:matplotlib.pyplot:Loaded backend module://ipykernel.pylab.backend_inline version unknown.
11. Create merging and plot dendrogram
We shall plot a dendrogram of the movies whose similarity measure will be given by the similarity distance we previously calculated. The lower the similarity distance between any two movies, the lower their linkage will make an intercept on the y-axis. For instance, the lowest dendrogram linkage we shall discover will be between the movies, It's a Wonderful Life and A Place in the Sun. This indicates that the movies are very similar to each other in their plots.
# Create mergings matrix
mergings = linkage(similarity_distance, method='complete')
# Plot the dendrogram, using title as label column
dendrogram_ = dendrogram(mergings,
labels=[x for x in movies_df["title"]],
leaf_rotation=90,
leaf_font_size=16,
)
# Adjust the plot
fig = plt.gcf()
_ = [lbl.set_color('r') for lbl in plt.gca().get_xmajorticklabels()]
fig.set_size_inches(108, 21)
# Show the plotted dendrogram
plt.show()
DEBUG:matplotlib.axes._base:update_title_pos
DEBUG:matplotlib.axes._base:update_title_pos
DEBUG:matplotlib.axes._base:update_title_pos
DEBUG:matplotlib.axes._base:update_title_pos
DEBUG:matplotlib.axes._base:update_title_pos

12. Which movies are most similar?
We can now determine the similarity between movies based on their plots! To wrap up, let's answer one final question: which movie is most similar to the movie Braveheart?
# Answer the question
ans = "Gladiator"
print(ans)
Gladiator